GPU HPL linpack
基础环境
1、硬件服务器:CPU、GPU、IB网卡
2、操作系统
3、GPU驱动,安装nvidia-fabricmanager
4、CUDA版本11.4
5、IB驱动
6、安装openmpi
性能测试
上传至文件系统或者GPU节点共享存储目录中
执行压测文件
[root@g90 ~]# cat startgpulinpack.sh
cd /home/software/gpulinpack/
ls
./run_1_5688M7_A800x8 &
[root@g90 ~]# ./startgpulinpack
[root@g90 gpulinpack]# cat run_1_5688M7_A800x8
#!/bin/bash
#location of HPL
HPL_DIR=`pwd`
#加载openmpi
export PATH=/home/software/openmpi-4.0.5/bin:$PATH
export INCLUDE=/home/software/openmpi-4.0.5/include:$INCLUDE
export LIBRARY_PATH=/home/software/openmpi-4.0.5/lib:$LIBRARY_PATH
export LD_LIBRARY_PATH=/home/software/openmpi-4.0.5/lib:$LD_LIBRARY_PATH
export MANPATH=/home/software/openmpi-4.0.5/share/man:$MANPATH
#查看mpirun版本
/home/software/openmpi-4.0.5/bin/mpirun --allow-run-as-root --version
#测试结果输出
TEST_NAME=run_1_5688M7_A800x8
DATETIME=`hostname`.`date +"%m%d.%H%M%S"`
mkdir ./results/HPL-$TEST_NAME-results-$DATETIME
echo "Results in folder ./results/HPL-$TEST_NAME-results-$DATETIME"
RESULT_FILE=./results/HPL-$TEST_NAME-results-$DATETIME/HPL-$TEST_NAME-results-$DATETIME-out.txt
nvidia-smi -pm 1
/home/software/openmpi-4.0.5/bin/mpirun --allow-run-as-root -np 8 -bind-to none -x LD_LIBRARY_PATH ./run_linpack_5688m7 2>&1 | tee $RESULT_FILE
# accumulated result summary
echo "RESULTS in $RESULT_FILE" >> ./results/result_summary.txt
grep "WC\|WR" $RESULT_FILE >> ./results/result_summary.txt
grep "WC\|WR" $RESULT_FILErun_1_5688M7_A800x8执行文件run_linpack_5688m7
[root@g90 gpulinpack]# cat run_linpack_5688m7
#!/bin/bash
#location of HPL
HPL_DIR=`pwd`
EXEC=${1:-xhpl}
APP="$HPL_DIR/$EXEC"
export UCX_MEMTYPE_CACHE=n
export UCX_TLS=dc,shm,cma,rc,mm,cuda_copy,cuda_ipc,gdr_copy
export UCX_RNDV_THRESH=16384
export UCX_RNDV_SCHEME=get_zcopy
export PATH=/home/software/openmpi-4.0.5/bin:$PATH
export INCLUDE=/home/software/openmpi-4.0.5/include:$INCLUDE
export LIBRARY_PATH=/home/software/openmpi-4.0.5/lib:$LIBRARY_PATH
export LD_LIBRARY_PATH=/home/software/openmpi-4.0.5/lib:$LD_LIBRARY_PATH
export MANPATH=/home/software/openmpi-4.0.5/share/man:$MANPATH
export CUDA_DEVICE_MAX_CONNECTIONS=16
export CUDA_COPY_SPLIT_THRESHOLD_MB=1
export TRSM_CUTOFF=9000000
export GPU_DGEMM_SPLIT=1.00
export MAX_D2H_MS=200
export MAX_H2D_MS=200
export SORT_RANKS=0
export GRID_STRIPE=8
export RANKS_PER_NODE=8
#export RANKS_PER_SOCKET=2
export RANKS_PER_SOCKET=4
export NUM_PI_BUF=6
export NUM_L2_BUF=6
export NUM_L1_BUF=6
export NUM_WORK_BUF=6
export TEST_SYSTEM_PARAMS=1
export ICHUNK_SIZE=768
export CHUNK_SIZE=3456
#export CHUNK_SIZE=6912 # for 64x32
#export SCHUNK_SIZE=224
#export ICHUNK_SIZE=5120
#export CHUNK_SIZE=5120
#export SCHUNK_SIZE=5120
#export ICHUNK_SIZE=1280
#export CHUNK_SIZE=5120
#export SCHUNK_SIZE=2560
#export OMP_NUM_THREADS=7
#export MKL_DYNAMIC=TRUE
export MKL_NUM_THREADS=8
export OMP_NUM_THREADS=8
#export OMP_NUM_THREADS=16
export OMP_PROC_BIND=TRUE
export OMP_PLACES=sockets
export TEST_LOOPS=1
#export TEST_SYSTEM_PARAMS=1
#export TEST_SYSTEM_PARAMS_COUNT=1
export MONITOR_GPU=1
export GPU_TEMP_WARNING=78
export GPU_CLOCK_WARNING=1275
#export GPU_CLOCK_WARNING=1320
export GPU_POWER_WARNING=410
export GPU_PCIE_GEN_WARNING=3
export GPU_PCIE_WIDTH_WARNING=2
case ${OMPI_COMM_WORLD_LOCAL_RANK} in
0)
#sudo nvidia-smi -rac > /dev/null
#sudo nvidia-smi -rgc > /dev/null
#sudo nvidia-smi -lgc 1350,1350
#sudo nvidia-smi -lgc 1380,1380
#nvidia-smi -ac 1593,1410
#sudo nvidia-smi -ac 1215,1335
#sudo nvidia-smi -lgc 1320,1320
#sudo nvidia-smi -lgc 1275,1275
#sudo nvidia-smi -lgc 1410,1410 > /dev/null
#sudo nvidia-smi -lgc 1320,1320 > /dev/null
#sudo nvidia-smi -lgc 1335,1335 > /dev/null
#sudo nvidia-smi -rac
#sudo nvidia-smi -ac 1215,1380
export CUDA_VISIBLE_DEVICES=0
export OMPI_MCA_btl_openib_if_include=mlx5_0:1
export UCX_NET_DEVICES=mlx5_0:1
#export UCX_NET_DEVICES=ib0
$PRE_APP numactl --physcpubind=0-51 --membind=0 $APP
;;
1)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=1
export UCX_NET_DEVICES=mlx5_1:1
export OMPI_MCA_btl_openib_if_include=mlx5_1:1
#export UCX_NET_DEVICES=ib1
$PRE_APP numactl --physcpubind=0-51 --membind=0 $APP
;;
2)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=2
export UCX_NET_DEVICES=mlx5_2:1
export OMPI_MCA_btl_openib_if_include=mlx5_2:1
#export UCX_NET_DEVICES=ib2
$PRE_APP numactl --physcpubind=0-51 --membind=0 $APP
;;
3)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=3
export UCX_NET_DEVICES=mlx5_3:1
export OMPI_MCA_btl_openib_if_include=mlx5_3:1
#export UCX_NET_DEVICES=ib3
$PRE_APP numactl --physcpubind=0-51 --membind=0 $APP
;;
4)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=4
export UCX_NET_DEVICES=mlx5_4:1
export OMPI_MCA_btl_openib_if_include=mlx5_4:1
#export UCX_NET_DEVICES=ib5
$PRE_APP numactl --physcpubind=52-103 --membind=1 $APP
;;
5)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=5
export UCX_NET_DEVICES=mlx5_6:1
export OMPI_MCA_btl_openib_if_include=mlx5_6:1
#export UCX_NET_DEVICES=ib6
$PRE_APP numactl --physcpubind=52-103 --membind=1 $APP
;;
6)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=6
export UCX_NET_DEVICES=mlx5_7:1
export OMPI_MCA_btl_openib_if_include=mlx5_7:1
#export UCX_NET_DEVICES=ib7
$PRE_APP numactl --physcpubind=52-103 --membind=1 $APP
;;
7)
nvidia-smi -ac 1593,1410
export CUDA_VISIBLE_DEVICES=7
export UCX_NET_DEVICES=mlx5_8:1
export OMPI_MCA_btl_openib_if_include=mlx5_8:1
#export UCX_NET_DEVICES=ib8
$PRE_APP numactl --physcpubind=52-103 --membind=1 $APP
;;
esac
[root@g90 gpulinpack]#
run_linpack_5688m7执行文件xhpl
性能分析
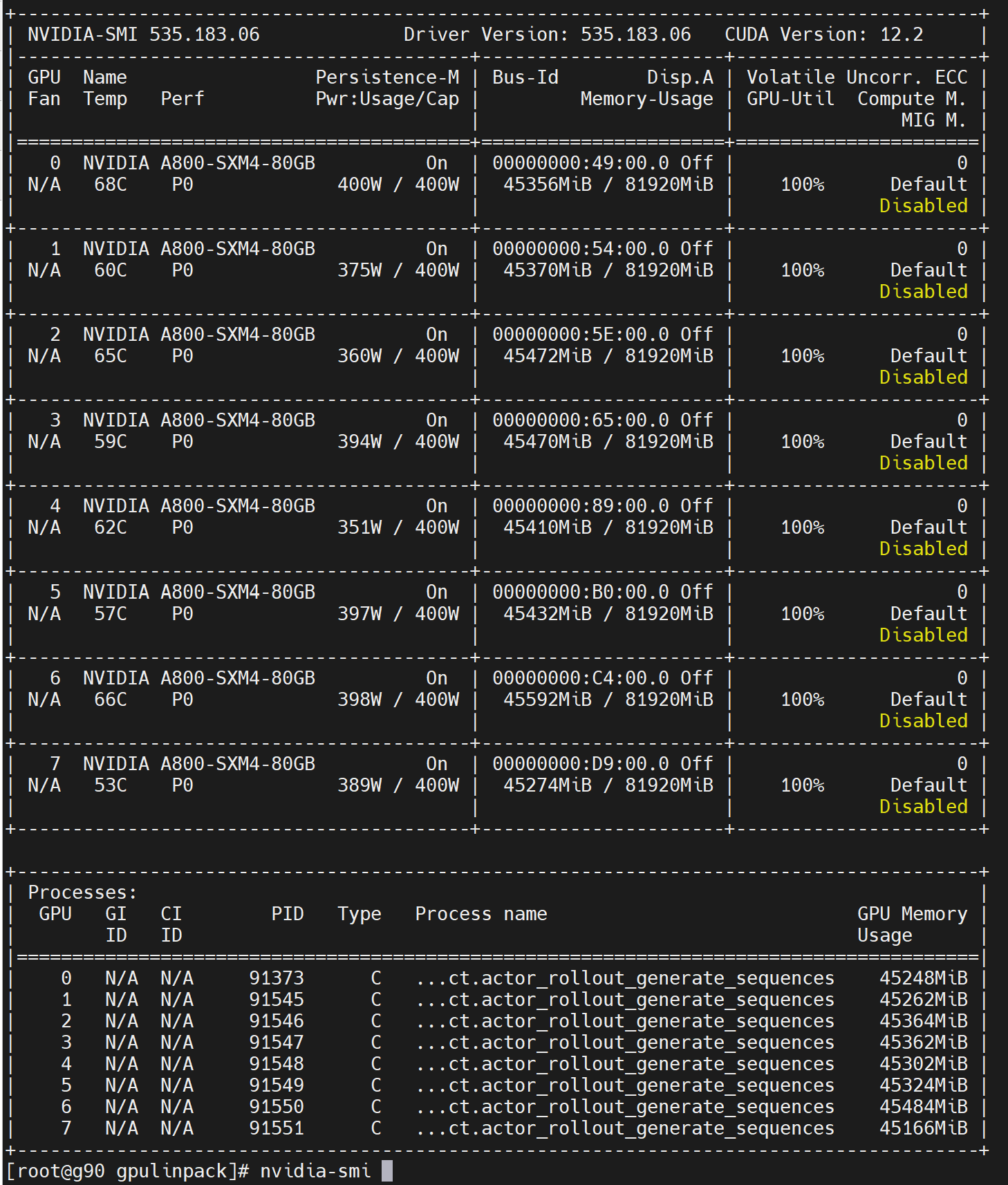
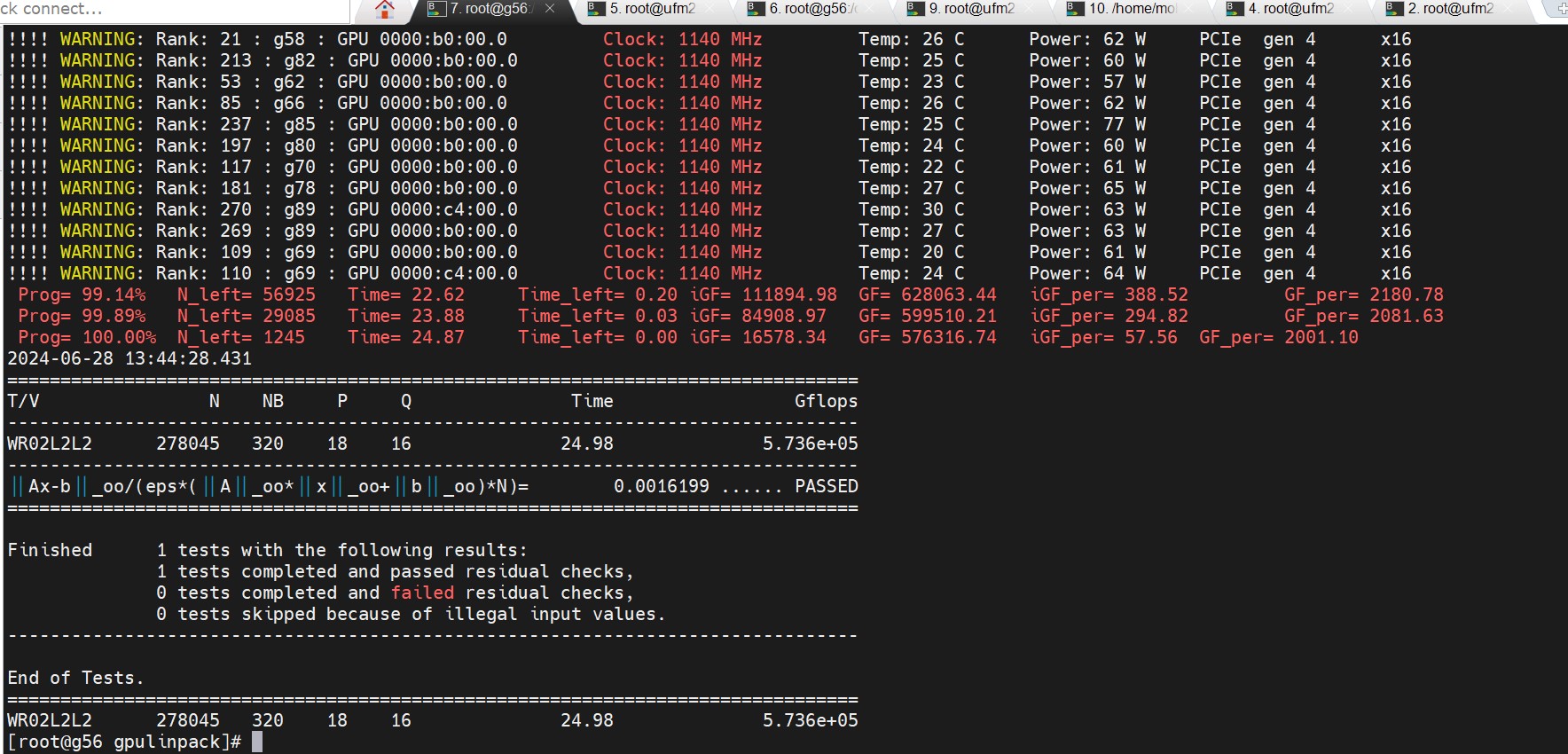
单卡A800理论值FP64 Tensor Core 19.5TFLOPS
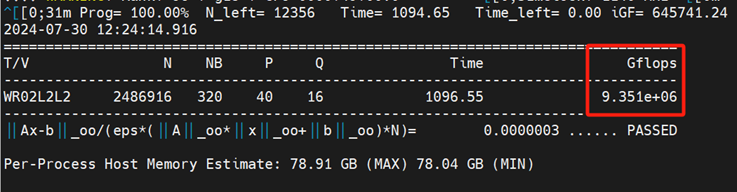
实测80台640张A800联合压测GPU HPL Linpack算力:
理论12480 Tflops
实测 9351 Tflops
这个AI GPU集群实测效率=9351/80/8/19.5=75%



